[혼자 공부하는 머신러닝+딥러닝] 11강 로지스틱 회귀로 와인 분류하기 & 결정 트리
레드와인과 화이트 와인 표시가 누락되었다.
캔에 인쇄된 알코올 도수, 당도, PH 값으로 와인 종류를 구별할 수 있는 방법이 있을 까?
알코올 도수, 당도, PH 값에 로지스틱 회귀 모델을 적용할 계획을 세웁니다.
먼저 화이트 와인을 양성클래스로 둡니다. : 1

와인 샘플 데이터를 불러 옵니다.
여기서는 새로운 메서드 2개가 등장하는데
info(), describe() 입니다.
1) info()
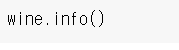

2. describe()

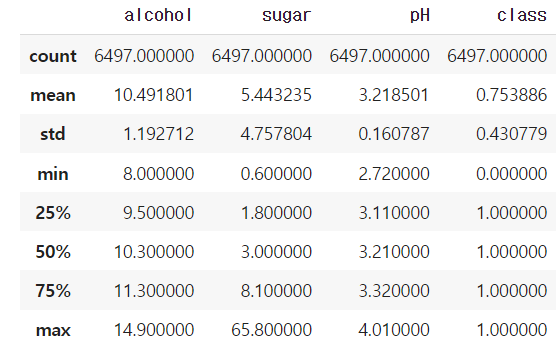
평균, 표준편차 등 여러 값들을 볼 수 있다. 전체 data가 어떻게 분포되어있는 지 확인이 가능하다.
근데 여기서 문제점이 하나 있다. data의 스케일이 다르다는 것이다. 이러면 후에 문제가 생긴다.
스케일을 맞게 변경한다.


훈련세트를 전처리해주었고, 그 다음 같은 객체를 사용해 테스트 세트를 변환하였다.
이제는 표준점수로 변환된 train_scaled와 test_scaled를 사용해 로지스틱 회귀 모델을 훈련할 것이다.

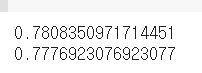
결과를 보니 훈련세트에서는 78%정도 화이트와인을 구분했고
테스트 세트에서는 77.7% 정도 화이트 와인을 구분했습니다.
음... 점수가 높지 않군요?
생각보다 힘든 일인가 봅니다. 훈련세트와 테스트 세트의 점수가 모두 낮으니 모델이 과소적합 된 것 같습니다.
일단 이거라도 보고를 해야합니다. 이 모델을 설명하기 위해 로지스틱 회귀가 학습한 계수와 절편을 출력해봅니다.

허허 이 로지스틱 회귀 모델을 잘 이해할 수 있나요? 우리는 이 모델이 왜 저런 계수 값을 학습했는 지 정확히 이해하기 어렵습니다. 그저 추측일 뿐이죠.
아마도 알코올 도수와 당도가 높을 수록 화이트 와인일 가능성이 높고, pH 가 높을 수록 레드 와인일 가능성이 높은 것 같습니다. 하지만 정확히 이 숫자가 어떤 의미인지 설명하긴 어렵습니다.
-> 대부분의 머신러닝 모델은 이렇게 학습 결과를 설명하기 어렵습니다.
이 보고서를 상부에 보고하면 어떻게 될까요? 당연히 이해하지 못하겠죠
이사님은 이렇게 말합니다.
" 조금 더 쉬운 방법은 없나요?"
"순서도 처럼 쉽게 설명해서 다시 가져오세요"

이럴 때 사용하는 것이 결정트리입니다.
결정트리는 어떤 질문을 통해서 data 훈련세트를 양쪽으로 나누는 것입니다.
스무고개랑 비슷하죠 질문을 하나씩 던져서 정답을 맞춰가는 것입니다.
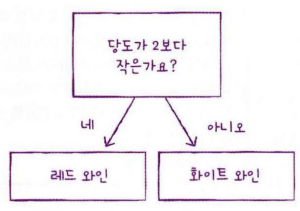
사이킷런이 결정 트리 알고리즘을 제공합니다.
fit() 메서드를 호출해서 모델을 훈련한 다음
score()메서드로 정확도를 평가해보겠습니다.

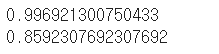
워후 훈련세트에 대한 점수가 엄청 높은 것을 볼 수 있습니다.
그에 비해 테스트 세트는 좀 떨어지네요 이 모델을 그림으로 표현해보겠습니다.

어마무시한게 나왔네요
맨위에 있는게 루트 노드, 마지막에 있는 게 리프노드입니다.
너무 복잡하죠? 이럴 때는 트리의 깊이를 제한해서 출력해봅니다.

max_depth를 통해서 깊이를 제한했습니다.
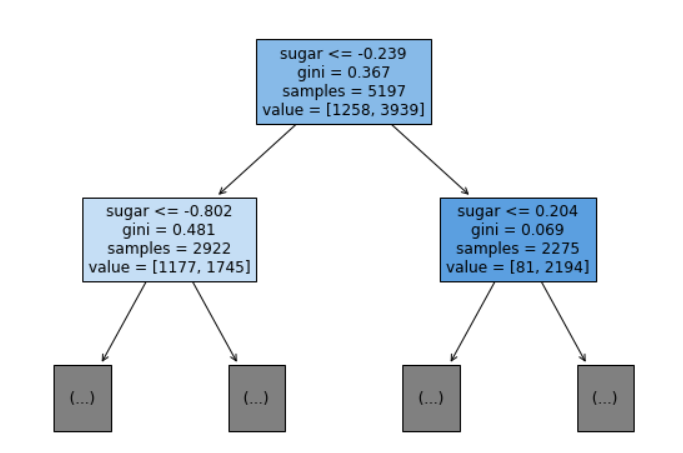
여기 보이는
gini는 불순도 기준을 얘기합니다.
value는 음성클래스와 양성클래스의 개수를 얘기합니다.
위에 있는 것은 루트노드
아래에 있는 것은 자식노드입니다.
<<불순도>>
DecisionTreeClassifier 클래스의 criterion 매개변수의 기본값이 'gini'입니다. criterion 매개변수의 용도는 노드에서 데이터를 분할할 기준을 정하는 것입니다.
앞에서 보인 트리에서 루트노드가 당도 -0.239를 기준으로 왼쪽과 오른쪽 노드로 나눈 것이 criterion 매개변수에 지정한 지니 불순도를 사용한 것입니다.
지니 불순도를 어떻게 계산하는 지 알아봅시다.

이전 그림을 참고하여 계산해보면

지니값이 0.367이 나온 것을 볼 수 있습니다.
결정트리 모델은 부모노드와 자식노드의 불순도 차이가 가능한 크게나오는 방향으로 노드를 분할합니다.
불순도 차이는 다음과 같이 계산합니다.

이런 부모와 자식 노드 사이의 불순도 차이를 정보이득이라고 합니다.
이 알고리즘은 정보 이득이 최대가 되도록 데이터를 나눕니다. 이는 더 좋은 예측을 만들 수 있도록 학습해나가는 것이 결정트리의 훈련방식이라는 것을 알 수 있습니다. 하지만 제한하지 않으면 리프노드가 순수노드가 될 때까지 트리를 성장시킵니다. 이는 너무 많은 트리를 생성하는 결과를 초래하고 이는 훈련세트에는 높은 점수를 테스트 세트에는 낮은 점수를 가져오는 과대적합을 발생시키는 것입니다.
그 현상을 줄이는 것이 바로 '가지치기' 입니다.

max_depth=3을 이용하여 더 이상 분할을 하지 않고 트리의 depth를 제한하였습니다.
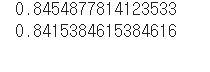
이 둘의 차이가 줄어든 것이 보이시나요?
훈련세트의 성능은 낮아졌지만 테스트 세트의 성능은 거의 그대로입니다.
이런 모델을 트리 그래프로 그려서 더 쉽게 이해해보겠습니다.


p.233을 참고하세요
리프노드 중 주황색을 띠고 있는 것이 레드와인입니다.
결정트리의 특징 중 하나로는 특성중요도 입니다. 특성 중요도는 어떤 특성이 가장 유용한지 나타냅니다. 아마도 깊이 1에서 당도를 사용했기 때문에 당도가 가장 유용한 특성 중에 하나일 겁니다.

순서대로 알코올 도수, 당도, ph입니다. 당도가 0.86 으로 sugar가 가장 중요하게 사용되었다는 것을 알 수 있겠죠?
-----
미무리 :
이 모델은 비록 테스트 세트의 성능이 아주 높지 않아서 많은 화이트 와인을 완벽하게 골라내지는 못하지만 이사님에게 보고하기에는 아주 좋은 모델입니다. ^^
전체 코드: