정형 데이터를 다루는 머신러닝 알고리즘 중 지금까지 배운 것 중에 가장 뛰어난 성능을 보이는게
오늘 배울 "트리 알상블 알고리즘"입니다.
앙상블이란? 여러개의 모델을 합쳐서 하나의결과를 만들어내는 것을 말합니다.
모델을 하나 훈련하는 것보다 여러개를 훈련해서 여러개의 모델이 내는 예측을 평균내던가 다수의 예측을 따라가던가 하는 게 낫습니다.
앙상블 중에서도 트리를 가지고 하는 것이 가장 효과적이고 가장 많이 발전되어 있습니다. 트리는 가만히 내버려 두면 과대적합이 되잖아요??
굉장히 성능이 저하됩니다. 따라서 트리를 여러개 만들면 과대적합도 줄일 수 있고 여러가지로 좋습니다!!
< 랜덤 포레스트 >
대표적인 앙상블 알고리즘입니다. 결정트리를 랜덤하게 만들어서 숲을 만드는 그런 알고리즘인데요
앙상블 알고리즘의 특징은 랜덤이 많이 들어간다는 것입니다. 무작위성을 줘서 일부러 트리의 성능을 낮추는 그런 효과를 내게 만듭니다.
랜덤포레스트 훈련방법은 부트스트랩 샘플을 사용합니다.
부트스트랩 샘플링은
1. 원래 훈련세트_ 5개의 샘플 있음 _ 각각 다른 모양
원래의 훈련세트에서 랜덤하게 샘플링을 합니다.
원래 샘플과 개수가 똑같게 5개씩 골라요 -> 동일한 샘플이 중복되어 골라질 수 있습니다. -> 중복을 허용한 샘플링입니다.
이렇게 만든 샘플을 가지고 결정트리를 훈련합니다.
예측도 하지요.
예측하는 방법은 확률을 모두 더해서 트리의 개수로 나누면 됩니다.
--
마무리 : 랜덤 포레스트의 예측하는 방법까지 알아보았습니다. 그런데 이렇게만 하느게 아니라 하나 더 있습니다.
결정트리 하나를 만들때 특성을 사용하는데
전체 특성이 3개가 있지만 3개가 아니라 루트3만큼 줄여서 특성을 사용합니다.
랜덤하게 3개 중에서 2개를 골라서 2개를 가지고 최선의 특성분할을 찾는 것입니다.
이런식으로 노드분할을 할 때 최적의 분할을 하지 못하도록 훼방을 놓는 것 -> 랜덤하게 무작위성을 주입하는 방식을 사용합니다.
즉 훈련세트를 랜덤하게 선택하고 노드를 분할을 할 후보특성을 랜덤하게 선택하면 트리가 성능이 너무 강력해지는 것을 막을 수 있습니다. -> 트리가 과대적합 되는 것을 막아주고 이렇게 하면 당연히 성능이 떨어지겠죠?
개별 트리의 성능은 낮아지지만 이런 낮은 성능의 트리를 여러개 묶어서 일반화하면 전체적으로 높은 성능이 나오고 검증세트나 테스트세트의 점수도 낮지 않은 모델을 만들 수있습니다!
코드를 한 번 살펴보도록 하겠습니다.
사이킷런의 RandomForestClassifier 클래스를 화이트 와인을 분류하는 문제에 적용해 봅시다.
앙상블 알고리즘들은 사이킷런의 앙상블 모듈 밑에 있습니다.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
wine = pd.read_csv('https://bit.ly/wine_csv_data')
data = wine[['alcohol','sugar','pH']] . to_numpy()
target = wine['class'].to_numpy()
train_input, test_input, train_target, test_target = train_test_split(
data, target, test_size=0.2, random_state=42
)
from sklearn.model_selection import cross_validate
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(rf, train_input, train_target,return_train_score=True, n_jobs=-1)
print(np.mean(scores['train_score']), np.mean(scores['test_score']))cross_validate() 함수를 사용해 교차검증을 수행해보도록 하겠습니다.
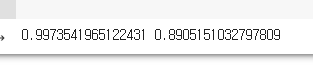
왼쪽 : 훈련세트 오른쪽 : 검증세트
훈련세트에 다소 과대적합 된 것 같습니다.
앞의 랜덤 포레스트 모델을 훈련세트에 훈련한 후 특성 중요도를 출력해보겠습니다.


'프로그래밍 > 혼자 공부하는 머신러닝 + 딥러닝' 카테고리의 다른 글
| 05-2 교차 검증과 그리드 서치 (0) | 2022.07.21 |
|---|---|
| [혼자 공부하는 머신러닝+딥러닝] 11강 로지스틱 회귀로 와인 분류하기 & 결정 트리 (0) | 2022.07.14 |
| [혼자 공부하는 머신러닝+딥러닝] 10강 확률적 경사 하강법 _ SGD Classifier (0) | 2022.07.13 |